Es posible que cuando estas escribiendo un programa, en algún momento necesites pausar la ejecución de un proceso llamando a la función sleep(NUMBER_OF_SECONDS) dependiendo del problema que estés resolviendo. En este post, compartiré lo que aprendí hasta ahora mientras investigaba los mecanismos internos del kernel que hacen que la función sleep funcione de la forma en que lo hace.
Agradezco su feedback. No soy un experto en este tema ya que las partes internas del Kernel de Linux son nuevas para mí, fue solo mi curiosidad lo que me llevó a revisar el código fuente del Kernel y quería compartir lo que aprendí. Si encuentran algo incorrecto en este post, pueden abrir un issue en el repositorio de Github de este blog. Gracias!.
Process State
Uno de los primeros conceptos que necesitamos revisar es el estado de un proceso. Un proceso en Linux tiene un estado asociado que representa su estado de ejecución en el sistema operativo. Un proceso puede estar en uno de los siguientes estados:
- Running
- Sleeping (interruptible and uninterruptible)
- Stopped
- Zombie
Cuando un proceso está ejecutando instrucciones en la CPU, se encuentra en estado “Running” y cuando el proceso está esperando que suceda algo, es decir, esperando I/O de red o disco, o se llama a la funcion sleep, cambiará a un estado Sleeping.
Podemos comprobarlo con un sencillo programa de ejemplo en C:
// states.c
// gcc states.c -o states
#include <stdio.h>
#include <unistd.h>
#define SOME_MAGIC_NUMBER 365000000l
void start_processing() {
long i;
printf("Starting Loop\n");
for (i = 0; i < (long)(10 * SOME_MAGIC_NUMBER); i++);
printf("Loop Finished\n");
}
int main() {
pid_t pid = getpid();
printf("PID: %d\n", pid);
start_processing();
printf("Sleep process\n");
sleep(5);
printf("Sleep finished\n");
start_processing();
return 0;
}
El código anterior ejecutará un loop durante algunos segundos, luego se suspenderá durante 5 segundos y finalmente ejecutará otro loop durante otro número de segundos. Por lo tanto, esperamos que el estado del proceso sea Running -> Sleeping -> Running.
Mientras se ejecuta el programa, podemos comprobar el estado del proceso con la herramienta Htop, que normalmente mostrará una letra en la octava columna que representa el estado del proceso, e.g. R (Running), S (Sleeping), T (Stopped), etc.
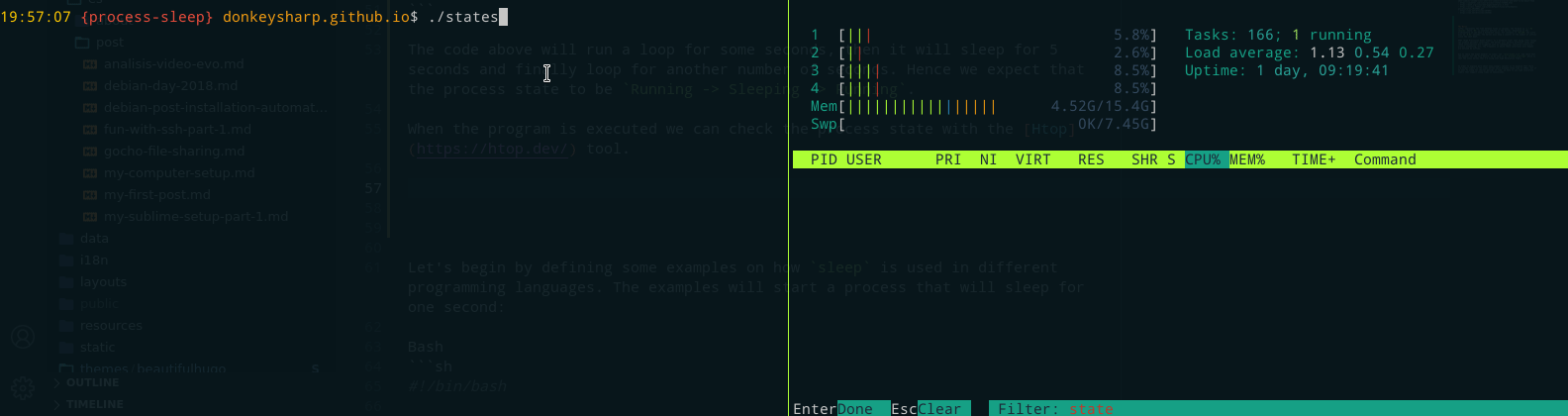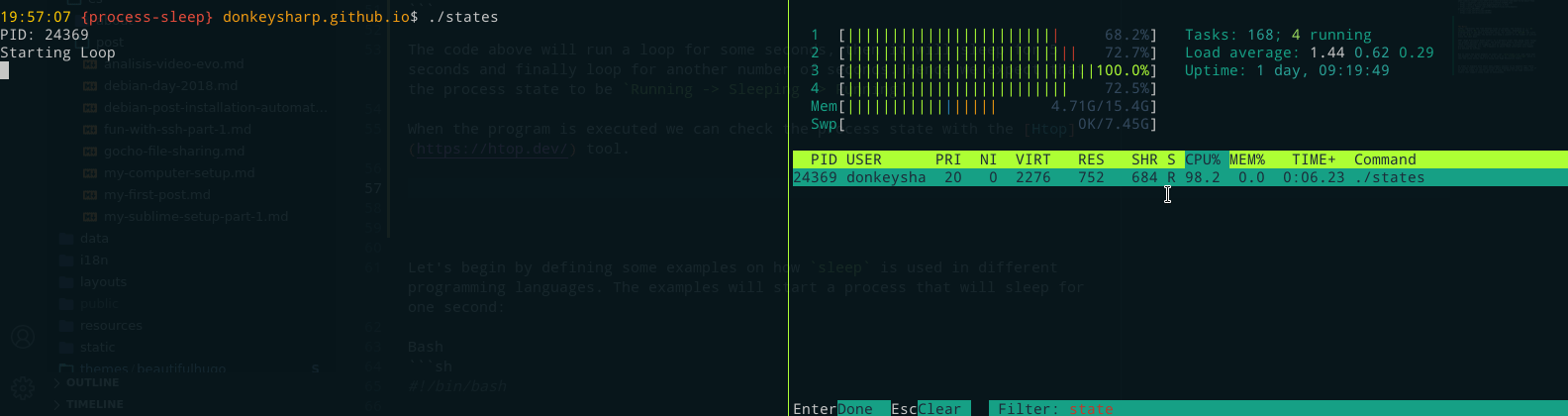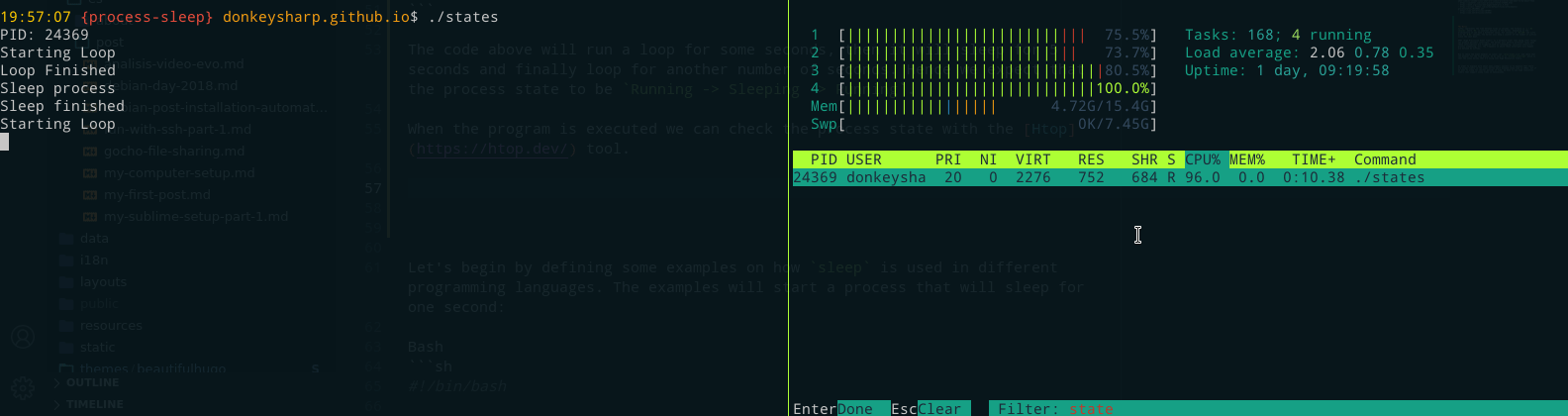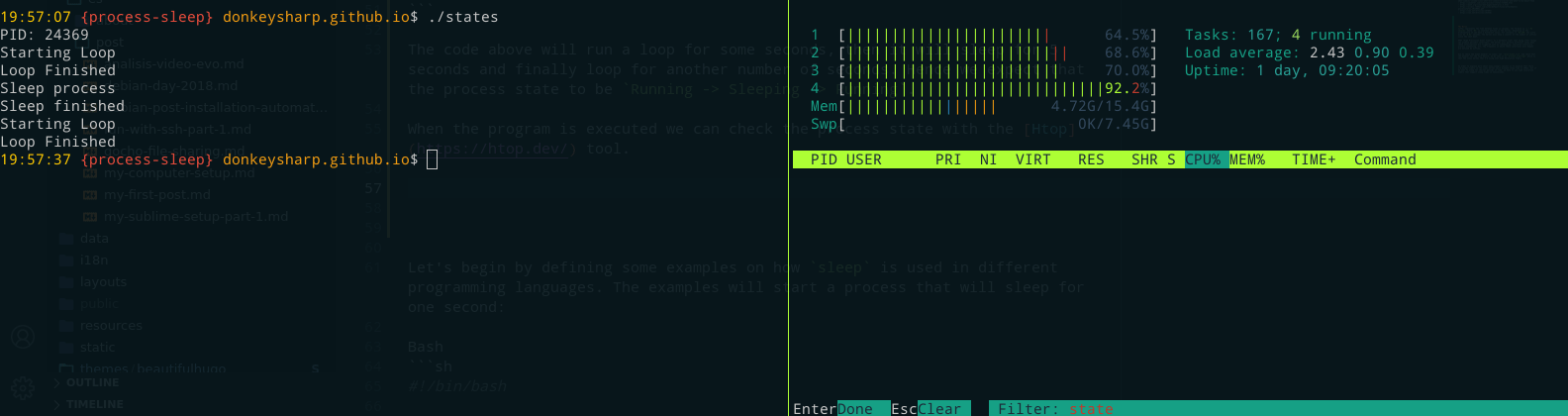
Como era de esperar, los estados que tenía el proceso durante la ejecución fueron: Running (R) -> Sleeping (S) -> Running (R).
TL;DR (super resumido)
Cuando un programa llama a la función sleep(NUMBER_OF_SECONDS) (en C), este usará la llamada al sistema (syscall) nanosleep. Otros lenguajes de programación usan diferentes syscalls que también pueden enviar un proceso a dormir durante algunos segundos, e.g. select.
La implementación del kernel de Linux de la syscall nanosleep hará lo siguiente:
- Inicializar un High Resolution sleep timer.
- Cambiar el estado del proceso a
TASK_INTERRUPTIBLE (Sleeping). - Inicia el High Resolution sleep timer.
- Indicar al scheduler de procesos para poner a otro proceso en ejecución y pausar la ejecución del proceso actual.
El kernel de Linux procesa los High Resolution Timers de la siguiente manera:
- El hardware de la computadora tiene un CPU timer que causa interrupciones periódicamente, haciendo que el kernel las maneje llamando a la función
hrtimer_interrupt. - La función
hrtimer_interruptprocesará los High Resolution Timers (a nivel de software) existentes y verá si un timer expiró. Una vez que un High Resolution Timer expire, el kernel llamará a la funciónhrtimer_wakeupque activará el proceso asociado con el timer, y eso cambiará el estado deTASK_INTERRUPTIBLE (Sleeping)aTASK_RUNNING (Running). - Finalmente, algunos ciclos de CPU más tarde, el scheduler de procesos continuará la ejecución del proceso exactamente donde se detuvo.
Sigue leyendo si está interesado en más detalles.
Yendo Más A Fondo
Como ingenieros de software, es probable que la mayor parte del tiempo estemos escribiendo aplicaciones que se ejecutan en user space o user mode, como servidores (de cualquier tipo) o aplicaciones del lado del servidor, web , aplicaciones móviles o de escritorio, scripts de automatización, etc.
No importa el lenguaje de programación, el framework o la tecnología, internamente un programa que se ejecuta en user mode siempre interactuará de una forma u otra con el sistema operativo (en este post Linux) a través de System Calls o syscalls. Por ejemplo, cuando leemos un archivo, nuestro código (sin importar el lenguaje de programación) se comunicará indirectamente con el Kernel de Linux a través de la syscall read (no es la única), luego el kernel le pedirá al disco duro físico el contenido del archivo que queremos basado en el sistema de archivos, y finalmente devolverá el contenido solicitado a nuestro programa.
Hay una herramienta llamada Strace que monitorea todas las syscall que ejecuta un proceso.
Si ejecutamos el ejemplo anterior en C usando strace, podemos ver la siguiente salida:
$ strace ./states
... syscalls for process loading (they won't be useful right now) ...
write(1, "PID: 26846\n", 11PID: 26846
) = 11
write(1, "Starting Loop\n", 14Starting Loop
) = 14
write(1, "Loop Finished\n", 14Loop Finished
) = 14
write(1, "Sleep process\n", 14Sleep process
) = 14
nanosleep({tv_sec=5, tv_nsec=0}, 0x7ffefc933be0) = 0
write(1, "Sleep finished\n", 15Sleep finished
) = 15
write(1, "Starting Loop\n", 14Starting Loop
) = 14
write(1, "Loop Finished\n", 14Loop Finished
) = 14
exit_group(0) = ?
+++ exited with 0 +++
La salida verdadera es más larga que la que se muestra arriba, pero la mayoría de las primeras syscalls siempre se ejecutan cuando se inicia un proceso y carga la biblioteca estándar de C entre otras cosas, pero las que nos interesa revisar son las últimas.
La syscall write le dice al Kernel que el programa quiere mostrar una cadena de texto en la salida estándar (en este caso la terminal). Con esa información, podemos tener una idea de que la función printf se comunica con el sistema operativo llamando a la syscall write.
Luego se llama a la syscall nanosleep, que indicará al kernel de Linux que mueva el proceso de un estado Running a un estado Sleeping.
Antes de revisar la implementación en Linux de la syscall nanosleep, primero tenemos que revisar un par de conceptos para tener una mejor comprensión de lo que viene.
High Resolution Timers
Dentro del kernel de Linux, diferentes componentes deben esperar un tiempo antes de ejecutar algo, aquí es donde entra el concepto de Timers. Un timer es una estructura (struct) en la que definimos su tiempo de expiración (el tiempo de espera) y qué función se llamará una vez que el timer expira.
El kernel de Linux tiene dos tipos de timers: Low Resolution Timers y High Resolution Timers. Revisaremos los Hight Resolution Timers.
El framework detrás de los High Resolution Timers dentro del kernel de Linux es un conjunto de structs y funciones que procesan los timers de manera óptima. Su implementación se basa en una cola de timers que se ordenan por el timer que expirará más pronto. Para que esta cola sea eficiente, utiliza la estructura de datos Red Black Tree para que la inserción y la eliminación se puedan realizar en tiempo logarítmico.
Este framework es muy interesante como tal, en este artículo solo revisaremos cómo se usa y algunas partes específicas de su implementación. Para obtener más información sobre los detalles de implementación, lea [0], [1] y [2].
La gestión del tiempo o time management dentro del kernel de Linux es un tema muy interesante y la charla dada por Stephen Boyd titulada “Timekeeping In The Linux Kernel” [4] me dio una mejor comprensión de cómo el Kernel de Linux maneja las tareas relacionadas al tiempo, así como su complejidad. Esta charla me ayudó mucho. ¡Gracias!
Hardware Timer
La CPU (físicamente) tiene un reloj e internamente tiene un timer programable. En palabras simples, el objetivo principal de este timer es causar interrupciones periódicamente (muchas veces dentro de un segundo) para que el kernel pueda manejarlas. La frecuencia de estas interrupciones dependerá de la arquitectura que se especifique en el Kernel de Linux durante su compilación. El kernel de Linux abstrae esto como Clock Event Devices y hay un Clock Event Device por CPU. Se utiliza un Clock Event Device para programar la siguiente interrupción que se generará [3].
Cuando ocurre una interrupción del timer, el kernel de Linux lo manejará llamando a una función. [4] menciona que para los High Resolution Timers, la función hrtimer_interrupt es el manejador de las interrupciones del timer (revisaremos su código más adelante).
Otra forma de verificar qué manejador se utilizará, es revisar el archivo de solo lectura /proc/timer_list que contiene la lista de timers pendientes y los Clock Event devices.
En mi caso, validé que el manejador de estos dispositivos en mi máquina es efectivamente la función hrtimer_interrup.
# /proc/timer_list
....
Tick Device: mode: 1
Per CPU device: 0
Clock Event Device: lapic-deadline
max_delta_ns: 1916620707137
min_delta_ns: 1000
mult: 9624619
shift: 25
mode: 3
next_event: 14403083615478 nsecs
set_next_event: lapic_next_deadline
shutdown: lapic_timer_shutdown
periodic: lapic_timer_set_periodic
oneshot: lapic_timer_set_oneshot
oneshot stopped: lapic_timer_shutdown
event_handler: hrtimer_interrupt <<<<<<< the interrupt handler
retries: 1316
Tick Device: mode: 1
Per CPU device: 1
Clock Event Device: lapic-deadline
max_delta_ns: 1916620707137
min_delta_ns: 1000
mult: 9624619
shift: 25
mode: 3
next_event: 14403083615478 nsecs
set_next_event: lapic_next_deadline
shutdown: lapic_timer_shutdown
periodic: lapic_timer_set_periodic
oneshot: lapic_timer_set_oneshot
oneshot stopped: lapic_timer_shutdown
event_handler: hrtimer_interrupt <<<<<<< the interrupt handler
retries: 484
.... The rest of devices per CPU of my machine
Ahora que tenemos una idea de los High Resolution Timers y que la CPU tiene un timer de hardware que periódicamente causa interrupciones al kernel, podemos continuar con la syscall nanosleep.
Implementación de la syscall nanosleep en Linux
El Kernel de Linux es un proyecto enorme, miles de archivos y millones de líneas de código, navegar a través de ellos puede ser todo un desafío. Hay una herramienta online llamada LXR que ayuda a navegar el código fuente del Kernel de Linux de manera amigable. La URL del sitio es https://elixir.bootlin.com/linux/5.14/source.
Hasta ahora sabemos que la syscall nanosleep hace toda la magia para mover el estado del proceso de Running a Sleeping durante un determinado número de segundos, luego pasar al estado Running nuevamente. Ahora exploraremos el código fuente del kernel de Linux y revisaremos cuáles son los mecanismos internos detrás de ese comportamiento “simple”.
Primero, tenemos que verificar dónde está definida la syscall nanosleep. Después de buscar un poco en Google, encontré un documento que especifica cómo se definen las syscall en el kernel de Linux. Por lo tanto, tenemos que buscar SYSCALL_DEFINE2(nanosleep, ....), el 2 en SYSCALL_DEFINE2 indica el número de argumentos de la syscall. Sé que nanosleep tiene dos argumentos después de comprobar en su manual (todas las syscall tienen una página man(2)).
Después de buscar el término nanosleep en LXR, encontré que la syscall está definida en archivo kernel/time/hrtimer.c .
SYSCALL_DEFINE2(nanosleep, struct __kernel_timespec __user *, rqtp,
struct __kernel_timespec __user *, rmtp)
{
struct timespec64 tu;
if (get_timespec64(&tu, rqtp))
return -EFAULT;
if (!timespec64_valid(&tu))
return -EINVAL;
current->restart_block.nanosleep.type = rmtp ? TT_NATIVE : TT_NONE;
current->restart_block.nanosleep.rmtp = rmtp;
return hrtimer_nanosleep(timespec64_to_ktime(tu), HRTIMER_MODE_REL,
CLOCK_MONOTONIC);
}
Por supuesto, cada línea de código tiene su razón de ser, pero resaltaré la llamada a timespec64_to_ktime que convierte los argumentos de entrada de la syscall en la estructura ktime que es utilizada por el framework de High Resolution Timers. Finalmente, llama a la función hrtimer_nanosleep donde comienza toda la diversión.
Iré función por función en el orden en que son llamadas y explicaré las partes que considero relevantes:
La función hrtimer_nanosleep:
long hrtimer_nanosleep(ktime_t rqtp, const enum hrtimer_mode mode, const clockid_t clockid)
{
...
hrtimer_init_sleeper_on_stack(&t, clockid, mode);
hrtimer_set_expires_range_ns(&t.timer, rqtp, slack);
ret = do_nanosleep(&t, mode);
...
}
Hay tres partes relevantes aquí:
- La inicialización del High Resolution Timer (lo revisaremos más adelante)
- El tiempo de expiración del timer inicializado. Aunque parece una tarea simple, hay mucha lógica por debajo. Debido a que el Kernel de Linux funciona a nivel de hardware, para convertir el tiempo humano en tiempo de computadora tiene que usar algunas fórmulas que se basan en la constante HZ que varía según la arquitectura. Además, aparece el concepto de Jiffies. No entraré en más detalles, sin embargo [4] explica muy bien esta parte.
- Finalmente, llama a la función
do_nanosleepque tiene la lógica que envía un proceso a dormir.
La función hrtimer_init_sleeper_on_stack (que al final llama a __hrtimer_init_sleeper) asigna e inicializa un High Resolution Timer asociado con el proceso actual que se está ejecutando.
El atributo function del High Resolution Sleep Timer es la función callback, lo que significa que este atributo function se llamará después de que expire el High Resolution Timer. En este caso el valor del atributo function es la función hrtimer_wakeup que veremos más adelante (no se olviden de esto 😉).
static void __hrtimer_init_sleeper(struct hrtimer_sleeper *sl,
clockid_t clock_id, enum hrtimer_mode mode)
{
...
__hrtimer_init(&scicil->timer, clock_id, mode);
sl->timer.function = hrtimer_wakeup; // <<<<<< This function will be called after the timer expires
sl->task = current; // <<<<<< Associates the timer with the current process
}
En el kernel de Linux, la variable
currentes un puntero al proceso actual que se está ejecutando (en nuestro caso, el programa que llama a la funciónsleep).
Antes de continuar con la función do_nanosleep, haré un paréntesis sobre la función __hrtimer_init.
static void __hrtimer_init(struct hrtimer *timer, clockid_t clock_id,
enum hrtimer_mode mode)
{
...
timerqueue_init(&timer->node);
}
Mencioné que los High Resolution Timers usan una cola que por debajo es implementada utilizando un Red Black Tree. La llamada a las funciones timerqueue_init solo asigna e inicializa un nodo del Red Black Tree, sin embargo este nodo no es agregado al árbol aún.
Después de ese breve paréntesis, veamos qué sucede dentro de la función do_nanosleep.
Inicialmente pensé que el ciclo do/while itera hasta que High Resolution Timer expire (algo como un bucle infinito), sin embargo las cosas suceden de manera diferente.
static int __sched do_nanosleep(struct hrtimer_sleeper *t, enum hrtimer_mode mode)
{
struct restart_block *restart;
do {
set_current_state(TASK_INTERRUPTIBLE); // <<<< This causes the process to go to a Sleeping state
hrtimer_sleeper_start_expires(t, mode);
if (likely(t->task))
freezable_schedule();
hrtimer_cancel(&t->timer);
mode = HRTIMER_MODE_ABS;
} while (t->task && !signal_pending(current));
__set_current_state(TASK_RUNNING);
if (!t->task)
return 0;
restart = ¤t->restart_block;
if (restart->nanosleep.type != TT_NONE) {
ktime_t rem = hrtimer_expires_remaining(&t->timer);
struct timespec64 rmt;
if (rem <= 0)
return 0;
rmt = ktime_to_timespec64(rem);
return nanosleep_copyout(restart, &rmt);
}
return -ERESTART_RESTARTBLOCK;
}
Como se mencionó anteriormente, cuando se llama a la función sleep, el proceso actual pasará al estado Sleeping. Podemos ver que eso sucede en la línea que llama a la función set_current_state que cambia el estado del proceso actual a TASK_INTERRUPTIBLE (Sleeping).
La llamada a la función hrtimer_sleeper_start_expires llamará a otras funciones hasta que llame a __hrtimer_start_range_ns que a su vez llamará a enqueue_hrtimer, es en este punto donde el timer (nodo) inicializado antes se agrega a la estructura del Red Black Tree para que el timer pueda ser procesado más tarde.
Finalmente, la función freezable_schedule invoca al process scheduler para que haga schedule de otro proceso, porque el proceso actual current entró en suspensión y la ejecución de nuestro proceso se detiene aquí.
Cómo Despierta El Proceso?
Hasta ahora hemos comprobado que la implementación de nanosleep cambia el estado del proceso a TASK_INTERRUPTIBLE y pausa la ejecución del proceso.
Ahora que el estado del proceso está en el estado TASK_INTERRUPTIBLE, el process scheduler no considerará la ejecución del proceso hasta que el estado del proceso vuelva a TASK_RUNNING.
Mencionamos que el Hardware Timer causa interrupciones periódicas para que el Kernel de Linux pueda manejarlas llamando a la función hrtimer_interrupt en cada interrupción (varias veces en un segundo). Es en esta función donde se procesan los High Resolution Timers llamando a la función __hrtimer_run_queues.
static void __hrtimer_run_queues(struct hrtimer_cpu_base *cpu_base, ktime_t now,
unsigned long flags, unsigned int active_mask)
{
struct hrtimer_clock_base *base;
unsigned int active = cpu_base->active_bases & active_mask;
for_each_active_base(base, cpu_base, active) {
struct timerqueue_node *node;
ktime_t basenow;
basenow = ktime_add(now, base->offset);
while ((node = timerqueue_getnext(&base->active))) {
struct hrtimer *timer;
timer = container_of(node, struct hrtimer, node);
if (basenow < hrtimer_get_softexpires_tv64(timer))
break;
__run_hrtimer(cpu_base, base, timer, &basenow, flags);
if (active_mask == HRTIMER_ACTIVE_SOFT)
hrtimer_sync_wait_running(cpu_base, flags);
}
}
}
La función __hrtimer_run_queues iterará los timers en el Red Black Tree, recuerden que iterará comenzando por los timers que están más próximos a expirar. Algo a tener en cuenta aquí es que romperá el ciclo while si el timer aún no ha expirado (¿por qué tener iteraciones innecesarias si el header de la cola es un timer que no ha caducado aún?). Pero cuando el timer expire, llamará a la función __run_hrtimer. Como podemos ver, su implementación llamará al callback que configuramos durante la inicialización del High Resolution Timer.
static void __run_hrtimer(struct hrtimer_cpu_base *cpu_base,
struct hrtimer_clock_base *base,
struct hrtimer *timer, ktime_t *now,
unsigned long flags) __must_hold(&cpu_base->lock)
{
...
fn = timer->function; // <<<<< This fn function is pointing to the hrtimer_wakeup function
...
restart = fn(timer);
...
}
La función que se configuró como el callback durante la inicialización del High Resolution Timer fue la función hrtimer_wakeup.
static enum hrtimer_restart hrtimer_wakeup(struct hrtimer *timer)
{
struct hrtimer_sleeper *t =
container_of(timer, struct hrtimer_sleeper, timer);
struct task_struct *task = t->task;
t->task = NULL;
if (task)
wake_up_process(task); // <<<<<< Wake up the process!!
return HRTIMER_NORESTART;
}
Como podemos ver, esta función llamará a la función wake_up_process enviando el proceso (tarea) asociado con el High Resolution Timer como parámetro. La función wake_up_process, entre otras cosas, establecerá el estado del proceso en TASK_RUNNING.
Algunos ciclos de CPU más tarde, el process schduler reanudará la ejecución de nuestro proceso donde se detuvo (después de la llamada a la función freezable_schedule). Luego, el resto de la función do_nanosleep liberará memoria, eliminará el timer del Red Black Tree y continuará con la ejecución. ¡Y eso es todo!
Hay otras alternativas a nanosleep
La syscall nanosleep no es la única syscall que se puede usar para dormir un proceso. Por ejemplo, la función time.sleep de Python usa la syscall select por detrás, sin embargo, si revisamos la implementación de do_select que a su vez llama a la función schedule_hrtimeout_range, se nota que llama a la función schedule_hrtimeout_range que inicializa un High Resolution Timer y le dice al process scheduler que haga schedule de otro proceso (la misma lógica que con nanosleep).
Python sleep es un ejemplo, pero otros lenguajes posiblemente usan otras syscalls.
Comentarios Finales
Aunque llamar a la función sleep en nuestros programas puede ser algo trivial, todos los mecanismos que viven detrás de esa simple función son asombrosos. Cuando comencé a investigar para entender qué sucede cuando llamas a una función sleep, no me hubiera imaginado cuánto iba a aprender.
En caso de que haya partes de este post que sean incorrectas, puedenm abrir un issue en el repositorio de Github de este blog. ¡Muchas gracias!.