It is possible when you are writing code, at some point you might need to pause the execution of a process by calling the sleep(NUMBER_OF_SECONDS) function depending on the problem you are solving. In this post, I will share what I learned so far while investigating the internal kernel mechanisms that make the sleep function work the way it does.
I appreciate your feedback. I am not an expert on this topic as Linux Kernel’s internals are new for me, it was just my curiosity that drove me to get into kernel’s source code, and wanted to share what I learned. If you find something incorrect in this post, please let me know by opening an issue on this blog’s Github repository. I will really appreciate it!.
Process State
One of the first concepts that we need to review is the process state. A Linux process has a state associated which represents its execution state in the operating system. A process can be on one of the next states:
- Running
- Sleeping (interruptible and uninterruptible)
- Stopped
- Zombie
When a process is executing instructions in the CPU, it is in Running state and when the process is waiting for something to happen i.e. waiting for network or disk I/O, or it calls the sleep function, it will change to a Sleeping state.
We can verify it with a simple C example program:
// states.c
// gcc states.c -o states
#include <stdio.h>
#include <unistd.h>
#define SOME_MAGIC_NUMBER 365000000l
void start_processing() {
long i;
printf("Starting Loop\n");
for (i = 0; i < (long)(10 * SOME_MAGIC_NUMBER); i++);
printf("Loop Finished\n");
}
int main() {
pid_t pid = getpid();
printf("PID: %d\n", pid);
start_processing();
printf("Sleep process\n");
sleep(5);
printf("Sleep finished\n");
start_processing();
return 0;
}
The code above will run a loop for some seconds, then it will sleep for 5 seconds, and finally loop for another number of seconds. Hence we expect the process state to be Running -> Sleeping -> Running.
While the program is being executed we can check the process state with the Htop tool, which will usually show a letter on the 8th column that represents the process state e.g. R (Running), S (Sleeping), T (Stopped), etc.
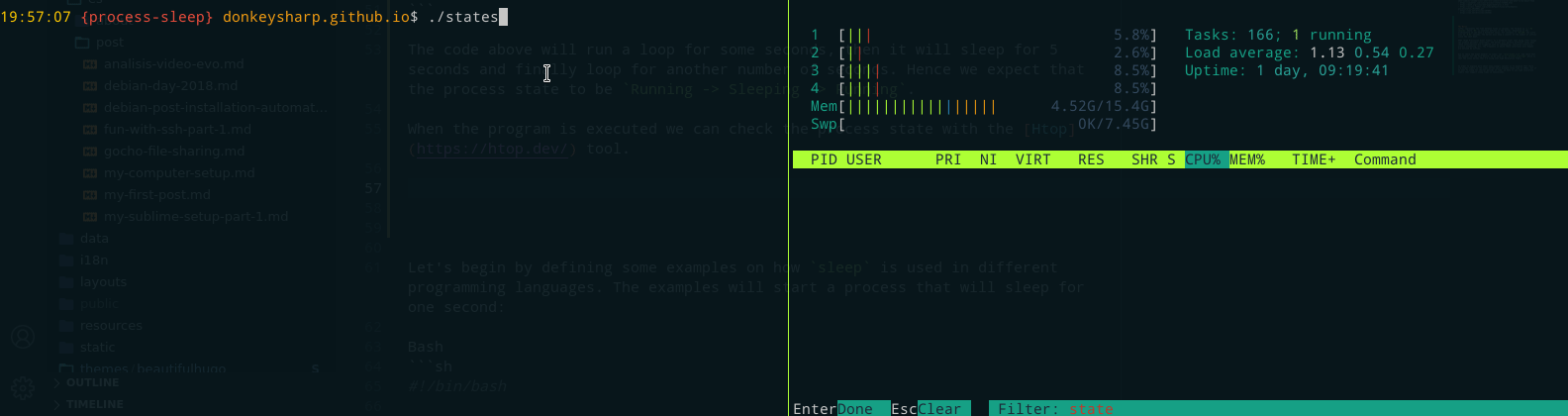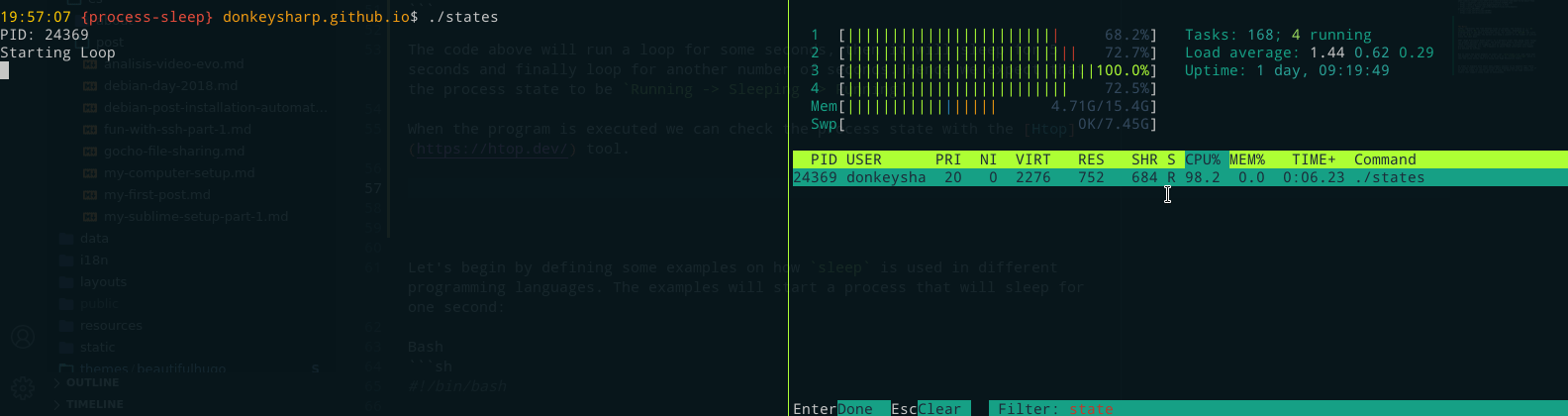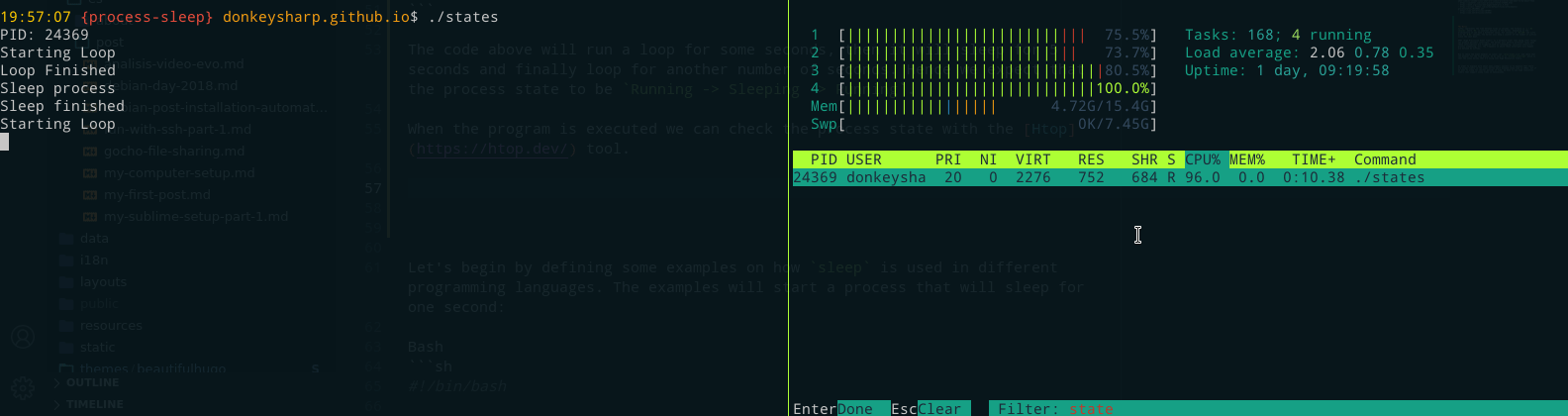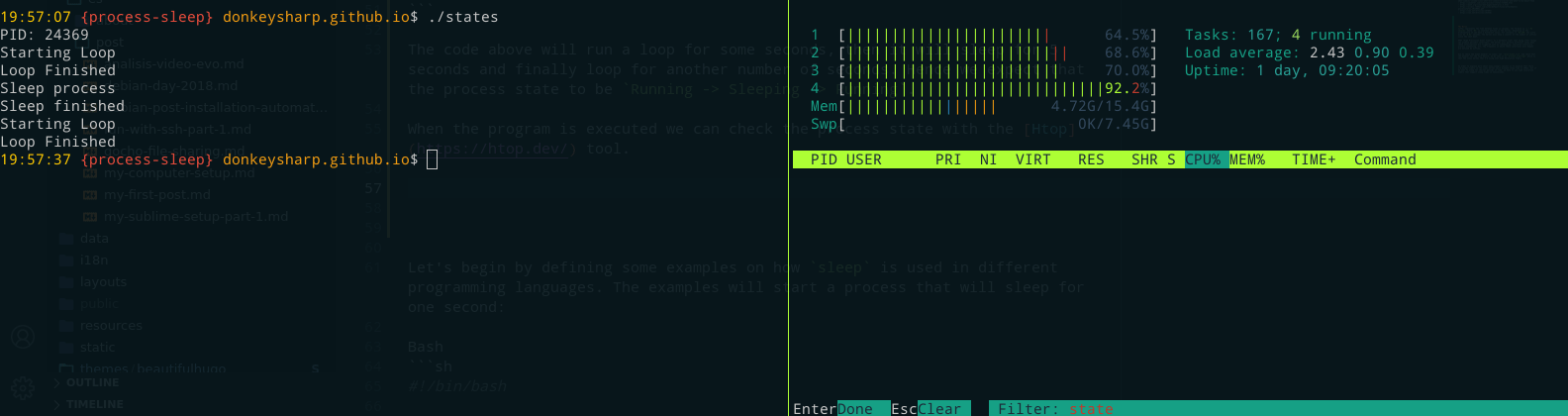
As expected, the states the process had while executing were: Running (R) -> Sleeping (S) -> Running (R).
TL;DR
When a program calls the sleep(NUMBER_OF_SECONDS) function (in C), it will call the nanosleep system call. Other programming languages might call other syscalls that can also send a process to sleep for some seconds e.g. select syscall, but inside the Linux kernel the behavior will be tsimilar no matter the syscall used.
The Linux Kernel implementation of the nanosleep system call will do the next:
- Initialize a High Resolution sleep timer.
- Change the process state to
TASK_INTERRUPTIBLE (Sleeping). - Starts the High Resolution sleep timer.
- Calls the process scheduler so it can schedule another process and pause the execution of the current process.
The Linux kernel processes High Resolution timers in following way:
- The computer hardware has a CPU Timer that will cause interruptions periodically, making the kernel handle them by calling the hrtimer_interrupt function.
- The
hrtimer_interruptfunction will process the existing timers and see if a timer expired. Once a High Resolution sleep timer expires, the kernel will call thehrtimer_wakeupfunction which will wake up the process associated with the timer, and that will change the state fromTASK_INTERRUPTIBLE (Sleeping)toTASK_RUNNING (Running). - Finally some CPU cycles later, the process scheduler will continue the execution of the process exactly where it was paused.
Continue reading if you are interested in more details.
Going Deeper
As software engineers most of the time we might be writing applications that run in user space or user mode such as servers (any kind) or server-side applications, web, mobile or desktop applications, automation scripts, etc.
No matter the programming language, framework, or technology, internally a program running in user mode will always interact one way or another with the operating system (for this post Linux) via System Calls or syscalls. For instance, when we read a file, our code (no matter the programming language) might indirectly communicate with the Linux Kernel via the read system call, then the kernel will ask the physical hard drive for the contents of the file we want based on the filesystem, and finally return the requested content to our program.
There is a tool called Strace that monitors all the system calls a process executes.
If we execute the previous C example using strace, we can see the following output:
$ strace ./states
... syscalls for process loading (they won't be useful right now) ...
write(1, "PID: 26846\n", 11PID: 26846
) = 11
write(1, "Starting Loop\n", 14Starting Loop
) = 14
write(1, "Loop Finished\n", 14Loop Finished
) = 14
write(1, "Sleep process\n", 14Sleep process
) = 14
nanosleep({tv_sec=5, tv_nsec=0}, 0x7ffefc933be0) = 0
write(1, "Sleep finished\n", 15Sleep finished
) = 15
write(1, "Starting Loop\n", 14Starting Loop
) = 14
write(1, "Loop Finished\n", 14Loop Finished
) = 14
exit_group(0) = ?
+++ exited with 0 +++
The real output is longer than the one showed above, but most of the first syscalls are always executed when a process starts and loads the C Standard Library among other things, but the ones we are interested to review are the last ones.
The write syscall tells the Kernel that the program wants to display a string on the standard output (in this case the terminal). With that information, we can have an idea that the printf function communicates with the operating system by calling the write syscall.
Then the nanosleep syscall is called, which will indicate the Linux kernel to move the process from a Running state to a Sleeping state.
Before reviewing the Linux implementation of the nanosleep syscall, first we have to review two concepts in order to have a better understanding of what’s coming.
High Resolution Timers
Inside the Linux Kernel, different components need to wait for some time before executing something, this is where the Timers concept comes in. A timer is a struct in which we define its expiration time (the time to wait) and what function will be called once the timer expires.
The Linux Kernel has two types of timers: Low Resolution timers and High Resolution timers. We are going to review High Resolution Timers.
The High Resolution Timers framework inside the Linux Kernel is a set of structs and functions that optimally process timers. Its implementation is based on a queue of timers that are sorted by the timer that is sooner to expire. In order to make this queue efficient, it uses a Red Black Tree data structure so insertion and deletion can be done in logarithmic time.
This framework is very interesting by itself, in this article we will only review how it is used and some specific parts of its implementation. For more information regarding implementation details read [0], [1] and [2].
Time management inside the Linux Kernel is a very interesting topic and the talk given by Stephen Boyd titled “Timekeeping In The Linux Kernel” [4] gave me a better understanding of how the Linux Kernel handles time-related tasks as well as its complexity. This talk helped me a lot. Thanks!
Hardware Timer
The CPU (physically) has a clock and internally it has a programmable timer. In simple words, the main purpose of this timer is to cause interruptions periodically (many times within a second) so the kernel can handle them. The frequency of these interruptions will depend on the architecture which is specified in the Linux Kernel during its compilation. The Linux Kernel abstracts this as Clock Event Devices and there is one Clock Event device per CPU. A Clock Event Device is used to schedule the next event interrupt [3].
When a timer interruption happens, the Linux Kernel will handle it by calling a function. [4] mentions that for High Resolution Timers the hrtimer_interrupt function is the handler for Timer interruptions (we will review its code later).
Another way to check which handler will be used, is to review the /proc/timer_list read-only file that contains the list of pending timers and the Clock Event devices.
In my case, I validated that the handler for these devices on my machine is indeed the hrtimer_interrup function.
# /proc/timer_list
....
Tick Device: mode: 1
Per CPU device: 0
Clock Event Device: lapic-deadline
max_delta_ns: 1916620707137
min_delta_ns: 1000
mult: 9624619
shift: 25
mode: 3
next_event: 14403083615478 nsecs
set_next_event: lapic_next_deadline
shutdown: lapic_timer_shutdown
periodic: lapic_timer_set_periodic
oneshot: lapic_timer_set_oneshot
oneshot stopped: lapic_timer_shutdown
event_handler: hrtimer_interrupt <<<<<<< the interrupt handler
retries: 1316
Tick Device: mode: 1
Per CPU device: 1
Clock Event Device: lapic-deadline
max_delta_ns: 1916620707137
min_delta_ns: 1000
mult: 9624619
shift: 25
mode: 3
next_event: 14403083615478 nsecs
set_next_event: lapic_next_deadline
shutdown: lapic_timer_shutdown
periodic: lapic_timer_set_periodic
oneshot: lapic_timer_set_oneshot
oneshot stopped: lapic_timer_shutdown
event_handler: hrtimer_interrupt <<<<<<< the interrupt handler
retries: 484
.... The rest of devices per CPU of my machine
Now we have an idea of High Resolution Timers and that the CPU has a hardware timer that periodically causes interruptions to the Kernel, we can continue with the nanosleep syscall.
Linux Kernel Implementation of nanosleep
The Linux Kernel is a big project, thousands of files and millions of lines of code, navigating through them can be challenging. There is an online tool called LXR that helps navigate the Linux Kernel source code in a friendly way. The URL of the site is https://elixir.bootlin.com/linux/v5.14/source.
So far we know that the nanosleep syscall does all the magic to move the process state from Running to Sleeping for a given number of seconds, then to Running state again. Now we will explore the Linux Kernel source code and review what are the internal mechanisms behind that “simple” behavior.
First, we have to check where the nanosleep syscall is defined. After googleing a little bit, I found a document that specifies how syscalls are defined in the Linux Kernel. Hence we have to search for SYSCALL_DEFINE2(nanosleep, ....), the 2 in SYSCALL_DEFINE2 indicates the number of arguments of the syscall. I know nanosleep has two arguments after reviewing its man page (all syscalls have a man page(2)).
After searching for the term nanosleep in LXR, I found that the syscall is defined in the kernel/time/hrtimer.c file.
SYSCALL_DEFINE2(nanosleep, struct __kernel_timespec __user *, rqtp,
struct __kernel_timespec __user *, rmtp)
{
struct timespec64 tu;
if (get_timespec64(&tu, rqtp))
return -EFAULT;
if (!timespec64_valid(&tu))
return -EINVAL;
current->restart_block.nanosleep.type = rmtp ? TT_NATIVE : TT_NONE;
current->restart_block.nanosleep.rmtp = rmtp;
return hrtimer_nanosleep(timespec64_to_ktime(tu), HRTIMER_MODE_REL,
CLOCK_MONOTONIC);
}
Of course, every line of code has its reason to be, but I will highlight the call to timespec64_to_ktime which converts the input arguments of the syscall to the ktime struct that is used by the High Resolution Timers framework. Finally, it calls the hrtimer_nanosleep where all fun starts.
I will go function by function in the order they are called and explain the parts I consider relevant:
hrtimer_nanosleep function:
long hrtimer_nanosleep(ktime_t rqtp, const enum hrtimer_mode mode, const clockid_t clockid)
{
...
hrtimer_init_sleeper_on_stack(&t, clockid, mode);
hrtimer_set_expires_range_ns(&t.timer, rqtp, slack);
ret = do_nanosleep(&t, mode);
...
}
There are three relevant parts here:
- The HR Sleep timer initialization (we will review this with more detail)
- The expiration time for the initialized timer. Although that seems a simple task, there is a lot of logic under the hood. Because the Linux Kernel works at the hardware level, to convert human time to computer time it has to use some formulas that are based on the HZ constant that varies depending on the architecture. Also, the concept of Jiffies comes up. I will not go into more details, however [4] explains this part very well.
- Finally, it calls the
do_nanosleepfunction that has the logic that sends a process to sleep.
The hrtimer_init_sleeper_on_stack function (which in the end calls the __hrtimer_init_sleeper function) allocates and initializes an HR sleep timer associated with the current process that is being executed.
The function attribute of the HR sleep timer is the callback function, which means that this function will be called after the HR sleep timer expires. In this case, the function attribute of the sleep timer is set to hrtimer_wakeup which we will see later (don’t forget this 😉).
static void __hrtimer_init_sleeper(struct hrtimer_sleeper *sl,
clockid_t clock_id, enum hrtimer_mode mode)
{
...
__hrtimer_init(&scicil->timer, clock_id, mode);
sl->timer.function = hrtimer_wakeup; // <<<<<< This function will be called after the timer expires
sl->task = current; // <<<<<< Associates the timer with the current process
}
In the Linux Kernel, the
currentvariable is a pointer to the current process being executed (in our case the program that calls thesleepfunction).
Before continuing with the do_nanosleep function, I will make a parenthesis about the __hrtimer_init function.
static void __hrtimer_init(struct hrtimer *timer, clockid_t clock_id,
enum hrtimer_mode mode)
{
...
timerqueue_init(&timer->node);
}
I mentioned that HR Timers use a queue which under the hood is implemented using a Red Black Tree. The call to timerqueue_init functions is only allocating and initializing a Red-Black Tree Node, but not adding it to the tree yet.
After that short parenthesis, let’s see what happens inside the do_nanosleep function.
I initially thought that the do/while loop iterates until the HR sleep timer expired (something like an infinite loop), things happen differently.
static int __sched do_nanosleep(struct hrtimer_sleeper *t, enum hrtimer_mode mode)
{
struct restart_block *restart;
do {
set_current_state(TASK_INTERRUPTIBLE); // <<<< This causes the process to go to a Sleeping state
hrtimer_sleeper_start_expires(t, mode);
if (likely(t->task))
freezable_schedule();
hrtimer_cancel(&t->timer);
mode = HRTIMER_MODE_ABS;
} while (t->task && !signal_pending(current));
__set_current_state(TASK_RUNNING);
if (!t->task)
return 0;
restart = ¤t->restart_block;
if (restart->nanosleep.type != TT_NONE) {
ktime_t rem = hrtimer_expires_remaining(&t->timer);
struct timespec64 rmt;
if (rem <= 0)
return 0;
rmt = ktime_to_timespec64(rem);
return nanosleep_copyout(restart, &rmt);
}
return -ERESTART_RESTARTBLOCK;
}
As mentioned before, when the sleep function is called, the current process will pass to a Sleeping state. We can see that happening on the line that calls the set_current_state function that changes the state of the current process to TASK_INTERRUPTIBLE (Sleeping).
The call to the hrtimer_sleeper_start_expires function will call other functions until it calls the __hrtimer_start_range_ns function which in turn will call the enqueue_hrtimer function, it is at this point where the timer (node) we initialized before is added to the Red Black Tree structure so the timer can be processed later.
Finally, the freezable_schedule function indicates the process scheduler to schedule another process because the current process went to sleep and the execution of our process pauses here.
How Does The Process Wakes Up?
So far we reviewed that the nanosleep implementation changes the state of the process to TASK_INTERRUPTIBLE and pauses the process execution.
Now that the process state is in TASK_INTERRUPTIBLE state, the process scheduler will not consider the process for execution in the future, until the state of the process is set back to TASK_RUNNING.
We mentioned that the Hardware Timer will cause periodic interrupts so the Linux Kernel can handle them by calling the hrtimer_interrupt function on each interruption (multiple times in a second). It is in this function where High Resolution Timers are processed by calling the __hrtimer_run_queues function.
static void __hrtimer_run_queues(struct hrtimer_cpu_base *cpu_base, ktime_t now,
unsigned long flags, unsigned int active_mask)
{
struct hrtimer_clock_base *base;
unsigned int active = cpu_base->active_bases & active_mask;
for_each_active_base(base, cpu_base, active) {
struct timerqueue_node *node;
ktime_t basenow;
basenow = ktime_add(now, base->offset);
while ((node = timerqueue_getnext(&base->active))) {
struct hrtimer *timer;
timer = container_of(node, struct hrtimer, node);
if (basenow < hrtimer_get_softexpires_tv64(timer))
break;
__run_hrtimer(cpu_base, base, timer, &basenow, flags);
if (active_mask == HRTIMER_ACTIVE_SOFT)
hrtimer_sync_wait_running(cpu_base, flags);
}
}
}
The __hrtimer_run_queues function will iterate the timers in the Red Black Tree, remember that it will iterate starting by the timers that are sooner to expire. Something to note here is that it will break the while loop if the timer didn’t expire yet (why do unnecessary iterations if the head of the queue is a timer that didn’t expire yet?). But when a timer expired, it will call the __run_hrtimer function. As we can see, its implementation will call the callback function we set during HR sleep timer initialization.
static void __run_hrtimer(struct hrtimer_cpu_base *cpu_base,
struct hrtimer_clock_base *base,
struct hrtimer *timer, ktime_t *now,
unsigned long flags) __must_hold(&cpu_base->lock)
{
...
fn = timer->function; // <<<<< This fn function is pointing to the hrtimer_wakeup function
...
restart = fn(timer);
...
}
The function that was set as the callback function during HR sleep timer initialization was the hrtimer_wakeup function.
static enum hrtimer_restart hrtimer_wakeup(struct hrtimer *timer)
{
struct hrtimer_sleeper *t =
container_of(timer, struct hrtimer_sleeper, timer);
struct task_struct *task = t->task;
t->task = NULL;
if (task)
wake_up_process(task); // <<<<<< Wake up the process!!
return HRTIMER_NORESTART;
}
As we can see this function will call the wake_up_process function sending the process (task) associated with the HR timer as parameter. The wake_up_process function among other things will set the process state to TASK_RUNNING.
Some CPU cycles later, the process scheduler will resume the execution of this process where it stopped (after the call to the freezable_schedule function). Then the rest of the do_nanosleep function will free memory, remove the timer from the Red Black Tree and continue with the execution. And that’s it!
There are other alternatives to nanosleep
The nanosleep syscall is not the only syscall that can be used to sleep a process. For example Python time.sleep function uses the select syscall under the hood, however, if we review the implementation of the do_select function which in turn calls the schedule_hrtimeout_range function, you will notice that it calls the schedule_hrtimeout_range function which initializes and starts a High Resolution sleep timer, and tells the process scheduler to schedule another process (same logic as with nanosleep).
Python sleep is one example, but other languages might be using different syscalls.
Last Comments
Although calling the sleep function in our programs might be something trivial, all the mechanisms that live behind that simple behavior are amazing. When I started digging to understand what happens when you call a sleep function, I wouldn’t have imagined how much I was going to learn.
In case there are parts of this post that you find incorrect, let me know by opening an issue on this blog’s Github repository. I will really appreciate it!.